Cassandra: Use Cases and Python CRUD Operations


Cassandra is a highly scalable and distributed NoSQL database known for its ability to handle large volumes of data across multiple nodes. It is designed to provide high availability and fault tolerance, making it a popular choice for applications that require real-time data processing and high read and write throughput. In this article, we will explore some common use cases for Cassandra and learn how to perform CRUD (Create, Read, Update, Delete) operations in Python using the Cassandra driver.
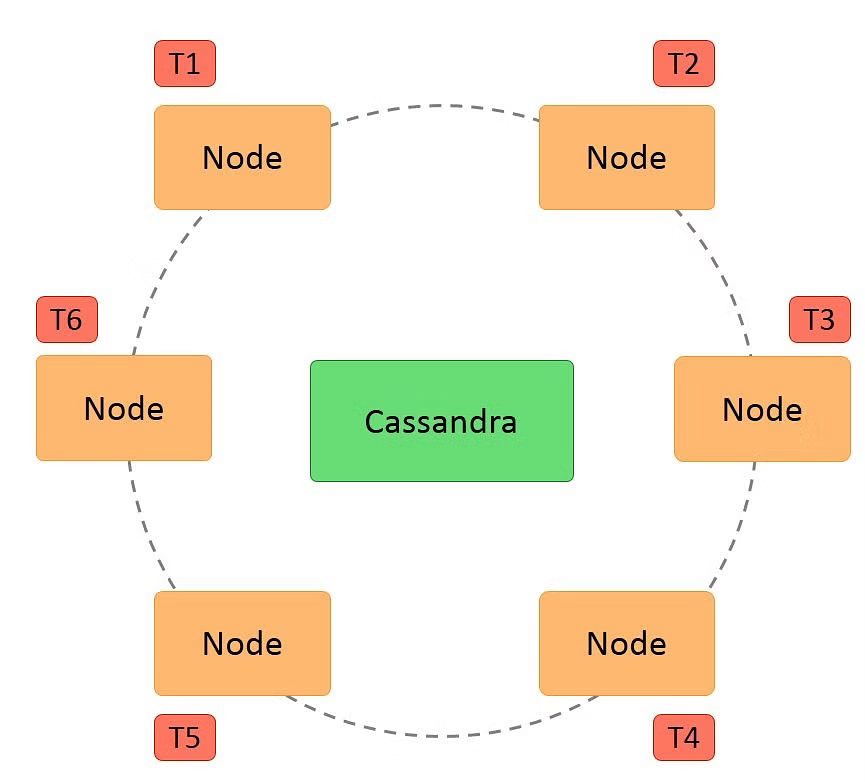
Cassandra’s Architecture
Cassandra uses a peer-to-peer architecture, which means that there is no central master node. All nodes in a Cassandra cluster are equal and can accept read and write requests.
[img src: link]
{kind=link}
Cassandra replicates data across multiple nodes to achieve high availability and durability. The replication factor specifies the number of copies of each data item that are stored in the cluster.
When to Use Cassandra?
1. High Write Throughput
Cassandra is very useful when your application demands lightning-fast write operations and low-latency data access. Cassandra's architecture is tailored for high write throughput. As it has a peer-to-peer architecture, it allows for horizontal scaling by adding more nodes. Each node can independently handle a significant number of write operations, making it suitable for real-time applications with massive write demands. Additionally, Cassandra's log-structured storage engine ensures efficient write operations, even during periods of high write traffic.
Social media platforms like Twitter or Instagram often experience a significant volume of user-generated content, such as tweets, photos, or videos. Users frequently create and post content, resulting in high write throughput. Read operations, while still important, might not be as frequent as write operations in such platforms.
2. Scalability for Growing Data
Cassandra's ability to scale out by adding more nodes seamlessly ensures your system can accommodate rapid data expansion without service disruptions.
In the case of an e-commerce platform facing seasonal traffic variations, Cassandra's scalability for growing data shines by effortlessly accommodating surges in user activity during peak seasons. It enables the platform to seamlessly scale out by adding nodes to the cluster, ensuring high performance, fault tolerance, and data distribution. This adaptability guarantees a consistent and responsive shopping experience for customers, whether during quiet periods or the busiest holiday seasons, without the need for significant downtime or schema changes.
3. High Availability and Fault Tolerance
In Cassandra, data is distributed across multiple nodes and replicated to ensure uninterrupted service.
For instance, consider a global e-commerce platform that employs Cassandra. In this setup, data is not only distributed across geographically dispersed data centers but also replicated within each data center. If one data center experiences an outage due to a network failure or other unforeseen events, user requests are automatically rerouted to another data center where the replicated data is readily available.
This design guarantees that even in the face of data center failures or network disruptions, the e-commerce platform can maintain uninterrupted operations, providing customers with a seamless shopping experience and ensuring business continuity.
4. Dynamic Schema Needs
Dynamic schema means that you have a requirement for a database system to accommodate changes or updates to the data schema without making significant alterations to the database structure. This flexibility is particularly valuable in situations where the data structure is subject to frequent modifications or when dealing with evolving data models.
A database system with dynamic schema support, like NoSQL databases including Cassandra, can easily handle these changes without requiring extensive schema migrations or downtime.
For instance, in a blogging platform powered by Cassandra, a blogger might decide to add a new field, such as "author's social media links" to their blog posts. In a dynamically schema-capable system, this change can be implemented without altering the entire database schema. New posts can include the new field, and existing posts can remain unaffected. This flexibility simplifies data management and allows the application to adapt swiftly to evolving user needs.
5. Time-Series Data Handling
When your application manages time-series data with data points collected at specific intervals, Cassandra is the go-to solution. It efficiently stores and retrieves such data, making it a valuable asset for applications like monitoring systems, log analytics, and sensor data storage.
Consider a weather monitoring system deployed across a region. Multiple weather stations continuously collect meteorological data, such as temperature, humidity, and wind speed, at regular intervals throughout the day. Cassandra efficiently stores and manages this time-series data, with each data point tagged with a timestamp and location information. Analysts and meteorologists can easily query the database to retrieve historical weather patterns, track changes over time, and generate forecasts, leveraging Cassandra's scalability, data distribution, and efficient querying capabilities to provide valuable insights for weather forecasting and research.
Performing CRUD Operations in Python
To get started, you'll need to install the cassandra-driver package:
pip install cassandra-driverConnecting to Cassandra
First, you need to establish a connection to your Cassandra cluster:
from cassandra.cluster import Cluster
# Connect to the Cassandra cluster
cluster = Cluster(['localhost']) # Replace 'localhost' with your cluster's contact points
session = cluster.connect()Creating a Keyspace and Table
Next, you'll create a keyspace and a table to store your data. Keyspaces act as high-level containers for your data, and tables define the schema for storing your records:
# Create a keyspace
session.execute("""
CREATE KEYSPACE IF NOT EXISTS my_keyspace
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1}
""")
# Switch to the keyspace
session.set_keyspace('my_keyspace')
# Create a table
session.execute("""
CREATE TABLE IF NOT EXISTS my_table (
id UUID PRIMARY KEY,
name text,
age int
)
""")
Performing CRUD Operations
Now, you can perform CRUD operations on your Cassandra table.
Create (Insert) Data
from uuid import uuid4
# Insert data
insert_query = session.prepare("""
INSERT INTO my_table (id, name, age)
VALUES (?, ?, ?)
""")
session.execute(insert_query, (uuid4(), 'John Doe', 30))Read Data
# Read data
select_query = session.prepare("""
SELECT * FROM my_table WHERE id = ?
""")
result = session.execute(select_query, [uuid4()])
for row in result:
print(row.name, row.age)
Update Data
# Update data
update_query = session.prepare("""
UPDATE my_table SET age = ? WHERE id = ?
""")
session.execute(update_query, (35, uuid4()))
Delete Data
# Delete data
delete_query = session.prepare("""
DELETE FROM my_table WHERE id = ?
""")
session.execute(delete_query, [uuid4()])These are the basic CRUD operations you can perform in Cassandra using Python. Remember that Cassandra's schema-less nature allows you to add and modify columns as needed, making it flexible for evolving data requirements.
When to Consider Alternatives to Cassandra?
1. Complex Queries and Joins:
Consider Other Databases: If your application heavily relies on complex queries, including JOIN operations or aggregations, Cassandra may not be the most efficient choice.Cassandra's distributed architecture and partitioning strategy distribute data across nodes based on primary keys. This design makes it challenging to perform efficient JOIN operations that involve multiple partitions, as it requires coordinating data retrieval from multiple nodes. Databases optimized for such operations, like PostgreSQL or MySQL, may better suit your needs.
2. Read-Heavy Workloads with Low Latency:
Seek Specialized Solutions: While Cassandra excels in write-heavy workloads, it may not provide the same low-latency performance for read-heavy scenarios as databases like Redis or Elasticsearch. Cassandra distributes data across multiple nodes in a cluster, which can lead to higher latency when reading data, especially when compared to in-memory databases like Redis. While Cassandra supports indexing, it may not match the read performance of databases like Elasticsearch, which are specifically optimized for complex text-based searches and aggregations.
3. Smaller to Medium-Sized Datasets:
Simpler Databases Apply: For applications dealing with smaller to medium-sized datasets, simpler databases such as PostgreSQL or MySQL may be more practical and easier to manage compared to the robust scalability of Cassandra. Cassandra's distributed nature and configuration can introduce complexity that may not be justified for smaller datasets.
4. Strict ACID Transaction Requirements:
Consider RDBMS: Cassandra's eventual consistency model can further complicate complex queries. In scenarios where you need strong ACID (Atomicity, Consistency, Isolation, Durability) guarantees for complex transactions, traditional relational databases like PostgreSQL or MySQL are better suited due to their strong consistency support.
Conclusion
Cassandra is a powerful NoSQL database that excels in handling large volumes of data with high availability and low-latency requirements. Its flexibility and scalability make it suitable for a wide range of use cases. With Python and the Cassandra driver, you can easily integrate Cassandra into your applications and perform CRUD operations as needed to manage your data efficiently.